 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the probability-quality paradox in language generation
Mar 31, 2022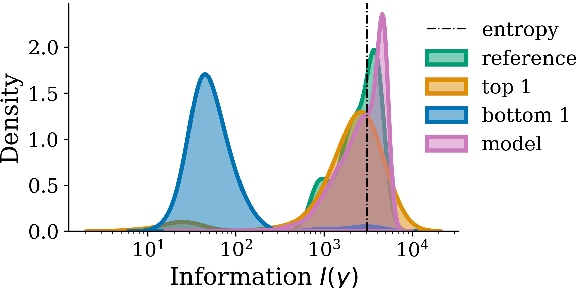
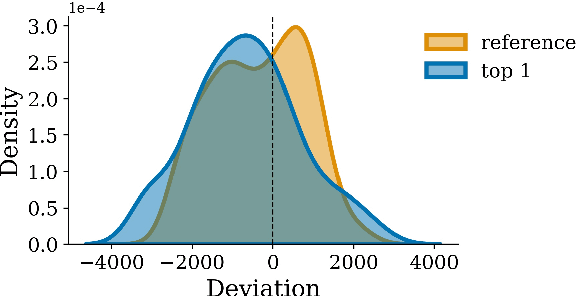
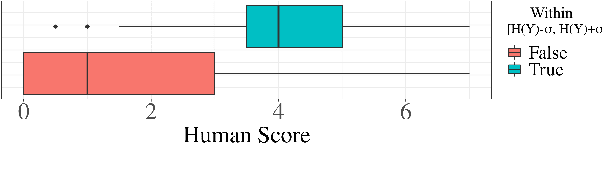
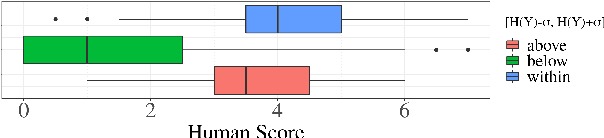
When generating natural language from neural probabilistic models, high probability does not always coincide with high quality: It has often been observed that mode-seeking decoding methods, i.e., those that produce high-probability text under the model, lead to unnatural language. On the other hand, the lower-probability text generated by stochastic methods is perceived as more human-like. In this note, we offer an explanation for this phenomenon by analyzing language generation through an information-theoretic lens. Specifically, we posit that human-like language should contain an amount of information (quantified as negative log-probability) that is close to the entropy of the distribution over natural strings. Further, we posit that language with substantially more (or less) information is undesirable. We provide preliminary empirical evidence in favor of this hypothesis; quality ratings of both human and machine-generated text -- covering multiple tasks and common decoding strategies -- suggest high-quality text has an information content significantly closer to the entropy than we would expect by chance.
On Decoding Strategies for Neural Text Generators
Mar 29, 2022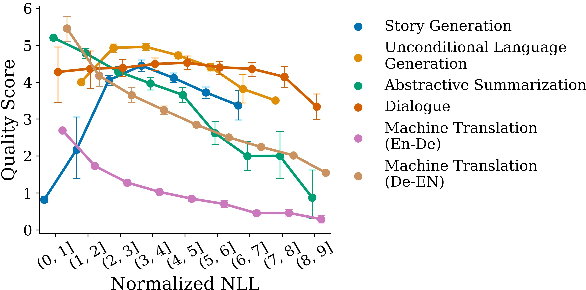

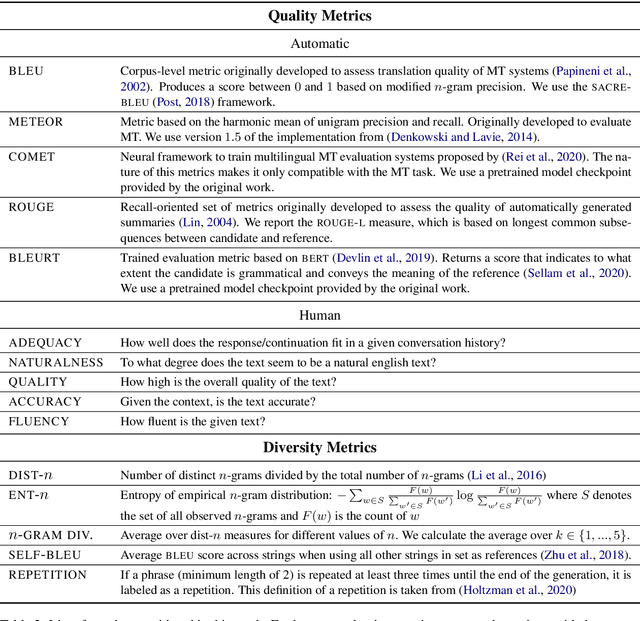
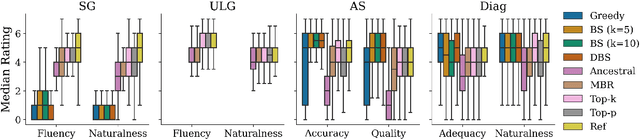
When generating text from probabilistic models, the chosen decoding strategy has a profound effect on the resulting text. Yet the properties elicited by various decoding strategies do not always transfer across natural language generation tasks. For example, while mode-seeking methods like beam search perform remarkably well for machine translation, they have been observed to lead to incoherent and repetitive text in story generation. Despite such observations, the effectiveness of decoding strategies is often assessed with respect to only a single task. This work -- in contrast -- provides a comprehensive analysis of the interaction between language generation tasks and decoding strategies. Specifically, we measure changes in attributes of generated text as a function of both decoding strategy and task using human and automatic evaluation. Our results reveal both previously-observed and surprising findings. For example, the nature of the diversity-quality trade-off in language generation is very task-specific; the length bias often attributed to beam search is not constant across tasks.
Typical Decoding for Natural Language Generation
Feb 10, 2022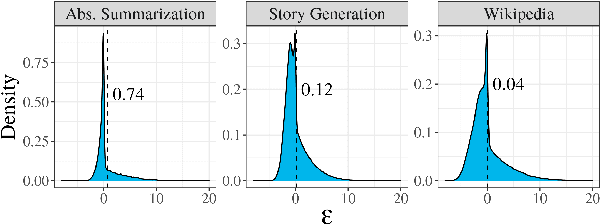
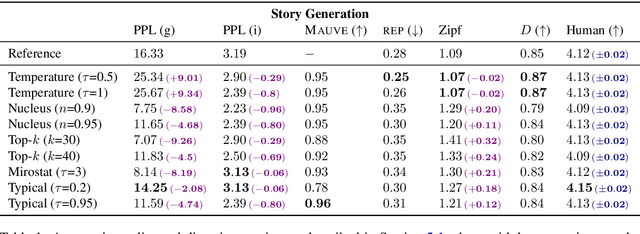
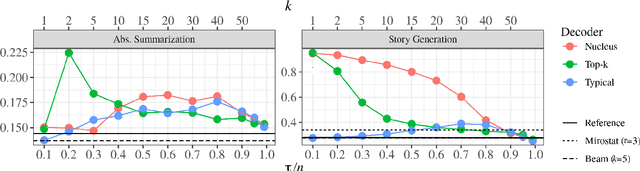
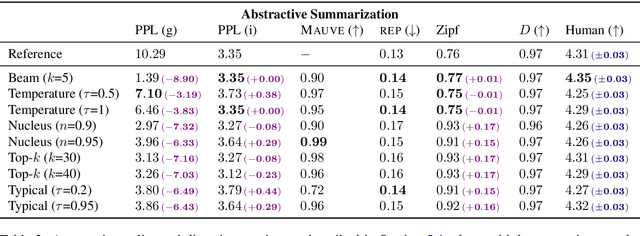
Despite achieving incredibly low perplexities on myriad natural language corpora, today's language models still often underperform when used to generate text. This dichotomy has puzzled the language generation community for the last few years. In this work, we posit that the abstraction of natural language as a communication channel (\`a la Shannon, 1948) can provide new insights into the behaviors of probabilistic language generators, e.g., why high-probability texts can be dull or repetitive. Humans use language as a means of communicating information, and do so in an efficient yet error-minimizing manner, choosing each word in a string with this (perhaps subconscious) goal in mind. We propose that generation from probabilistic models should mimic this behavior. Rather than always choosing words from the high-probability region of the distribution--which have a low Shannon information content--we sample from the set of words with an information content close to its expected value, i.e., close to the conditional entropy of our model. This decision criterion can be realized through a simple and efficient implementation, which we call typical sampling. Automatic and human evaluations show that, in comparison to nucleus and top-k sampling, typical sampling offers competitive performance in terms of quality while consistently reducing the number of degenerate repetitions.